
数据科学践行者的学习日记:Kaggle 平台的魅力与价值

作为数据科学领域的一块金字招牌,它已经成为全球最受欢迎的数据科学竞赛平台。在其上,每个竞赛题目都隐藏着来自全球各地的一大批身怀绝技的数据科学家。其采用众包模式,收取部分佣金将公司的数据挖掘问题发布在平台上,并设置高额奖金吸引数据科学家参与解决。每一位注册参赛者都可以免费获取竞赛题目和数据集,将自己的数据分析方案以报告的形式呈现在平台上供大家讨论。数据分析方案最终被公司采纳的选手将获得丰厚的奖金。
以我现在的水平,不敢贸然参加比赛,怕自己出的成绩排在最后。所以打算先拿几组题来练习,一方面锻炼自己的数据思维和分析能力,另一方面提高自己的R或者说能力。这次练习用的数据集叫NBA shot log.csv(在公众号后台回复“NBA”即可下载数据)。这个数据集包含了2014-15赛季30支NBA球队904场常规赛281名球员的近13万次投篮数据。数据包含了比赛双方、主客场、胜负、射手、防守球员、投篮距离、命中率等21个变量,可以根据分析目的自由进行数据挖掘建模。经过几天的摸索,结合之前数据高手的分析计划,我决定用两条推文展示一下对这个数据集的分析和挖掘。本文主要给大家展示数据集的探索性数据分析(EDA)和可视化。下一篇文章会将一些机器学习算法拟合到数据中,预测球员的投篮命中率。NBA shot log.csv 界面如下:
作为一个热爱数据分析、看了十几年篮球的编辑,不得不说NBA的数据真的很适合分析。经常看篮球的JR们可能都知道,休斯敦火箭队总经理莫雷迷信一套篮球数据分析理论,坚信有数据支撑的决策才是最好的决策。今年金州勇士队的夺冠和火箭队成功闯入西部第二轮,无疑为莫雷的理论提供了最好的事实佐证。虽然本文是探索性数据分析与可视化,但在分析之前我们无疑需要设定几个分析目标:
接下来我们将根据以上五个目标,利用R语言对数据集进行探索性数据分析与可视化。
读入数据后,快速浏览一下数据概览:
nba_shots<-read.csv("shot_logs.csv")
dim(nba_shots) #数据量
[1] 128069 21
str(nba_shots) #数据结构
Classes ‘tbl_df’, ‘tbl’ and 'data.frame': 128069 obs. of 21 variables:
$ GAME_ID : int 21400899 21400899 21400899 21400899 21400899 21400899 21400899 21400899 21400899 21400890 ...
$ MATCHUP : Factor w/ 1808 levels "DEC 01, 2014 - DEN @ UTA",..: 1291 1291 1291 1291 1291 1291 1291 1291 1291 1277 ...
$ LOCATION : Factor w/ 2 levels "A","H": 1 1 1 1 1 1 1 1 1 2 ...
$ W : Factor w/ 2 levels "L","W": 2 2 2 2 2 2 2 2 2 2 ...
$ FINAL_MARGIN : int 24 24 24 24 24 24 24 24 24 1 ...
$ SHOT_NUMBER : int 1 2 3 4 5 6 7 8 9 1 ...
$ PERIOD : int 1 1 1 2 2 2 4 4 4 2 ...
$ GAME_CLOCK : Factor w/ 719 levels "0:00","0:01",..: 70 15 1 228 155 615 136 600 434 213 ...
$ SHOT_CLOCK : num 10.8 3.4 NA 10.3 10.9 9.1 14.5 3.4 12.4 17.4 ...
$ DRIBBLES : int 2 0 3 2 2 2 11 3 0 0 ...
$ TOUCH_TIME : num 1.9 0.8 2.7 1.9 2.7 4.4 9 2.5 0.8 1.1 ...
$ SHOT_DIST : num 7.7 28.2 10.1 17.2 3.7 18.4 20.7 3.5 24.6 22.4 ...
$ PTS_TYPE : int 2 3 2 2 2 2 2 2 3 3 ...
$ SHOT_RESULT : Factor w/ 2 levels "made","missed": 1 2 2 2 2 2 2 1 2 2 ...
$ CLOSEST_DEFENDER : Factor w/ 473 levels "Acy, Quincy",..: 15 51 51 62 471 456 219 351 314 132 ...
$ CLOSEST_DEFENDER_PLAYER_ID: int 101187 202711 202711 203900 201152 101114 101127 203486 202721 201961 ...
$ CLOSE_DEF_DIST : num 1.3 6.1 0.9 3.4 1.1 2.6 6.1 2.1 7.3 19.8 ...
$ FGM : int 1 0 0 0 0 0 0 1 0 0 ...
$ PTS : int 2 0 0 0 0 0 0 2 0 0 ...
$ player_name : Factor w/ 281 levels "aaron brooks",..: 36 36 36 36 36 36 36 36 36 36 ...
$ player_id : int 203148 203148 203148 203148 203148 203148
加载分析所需的 R 包。在本文中,我们主要使用数据处理包 dplyr 和可视化包。
library(dplyr)
library(ggplot2)
球员的投篮选择
如今NBA盛行小球战术,强调三分球和内线突破,弱化中距离投篮。我们通过数据分析来看一下球员的投篮选择问题,选取了投篮距离、防守人距离等变量。我们先来看球员的投篮距离分布:
ggplot(nba_shots,aes(SHOT_DIST))+geom_histogram()
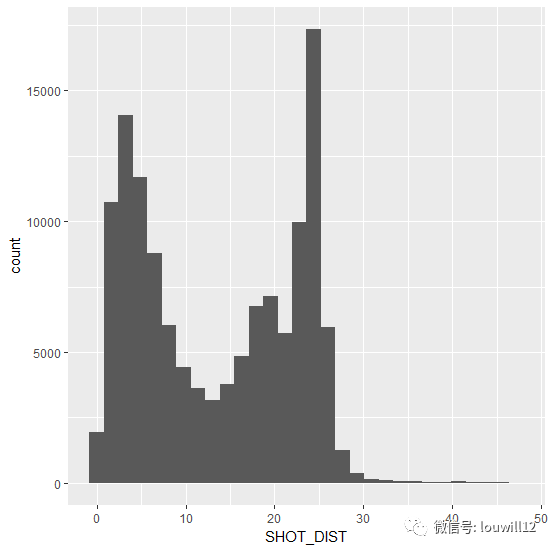
从投篮距离的柱状图分布中我们可以看出,如今球员的投篮距离呈双峰分布。简单的解释就是,球员更倾向于突破篮筐或者在三分线外投篮,而中距离投篮明显较少。禁区内的距离是0到10英尺,三分线外是22英尺。这个趋势明显符合图中的趋势。我们再来看看球员投篮时防守队员的位置分布:
ggplot(nba_shots,aes(CLOSE_DEF_DIST))+geom_histogram()+ xlim(0,20)
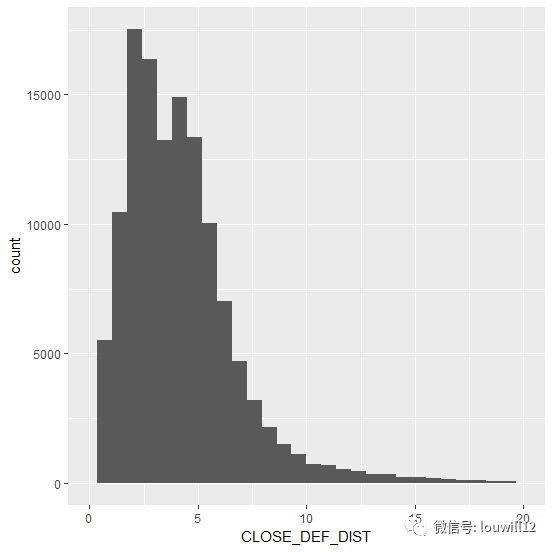
从防守队员位置分布图中我们可以看到,在大多数的投篮中,防守队员并没有完全失位,5英尺内的防守队员对投篮者都构成了足够的威胁。只有在少数快攻中,防守队员才会因为失位而放弃防守。这一方面说明NBA比赛的激烈程度相当高,另一方面也体现了NBA球员的技战术水平。
哪些因素与球员的投篮命中率有关?
熟悉篮球的JR们肯定都知道,场上防守的强度决定了对手的投篮命中率。我们来看看NBA球员投篮命中率相关的因素有哪些。选取投篮距离、防守者距离、投篮结果、运球次数、触球时间等变量:
ggplot(nba_shots,aes(SHOT_DIST, CLOSE_DEF_DIST))+
geom_point(aes(color=factor(SHOT_RESULT)))+
geom_vline(xintercept=c(15,22),color="blue")
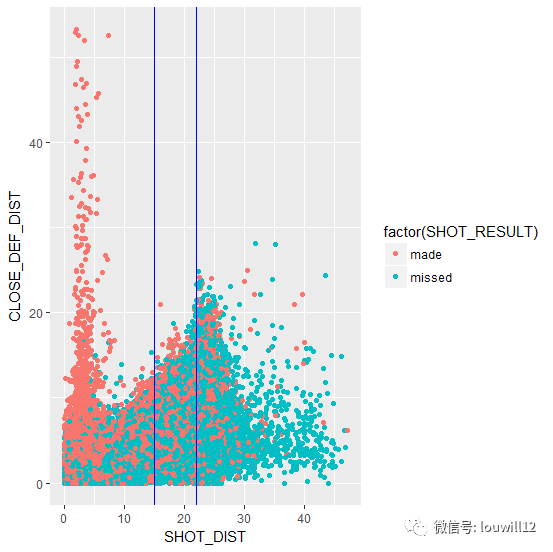
从上图可以看出,命中数在篮筐附近呈垂直分布,防守球员无处可寻。这是由于防守反击造成的快攻上篮或扣篮,而防守球员通常还在后场,已经放弃防守。我们在罚球线距离(15英尺)和三分线距离(22英尺)处画出两条蓝线。篮筐与罚球线距离之间有一个明显的低谷,这也反映出目前中距离投篮并不被NBA球队重视nba球队分布图,而三分线附近则有密集的投篮分布。各支球队在三分线的攻防上也下了足够的功夫。显然,在大量三分战术下,各支球队在三分线外的命中率依然不高。当然,整体的命中率依然是从篮筐到三分线逐渐递减的分布趋势。
我们来看看球员的运球时间、触球时间和成功投篮次数之间的关系:
ggplot(nba_shots,aes(DRIBBLES,TOUCH_TIME))+
geom_point(aes(color=factor(SHOT_RESULT)))+ylim(-10,20)
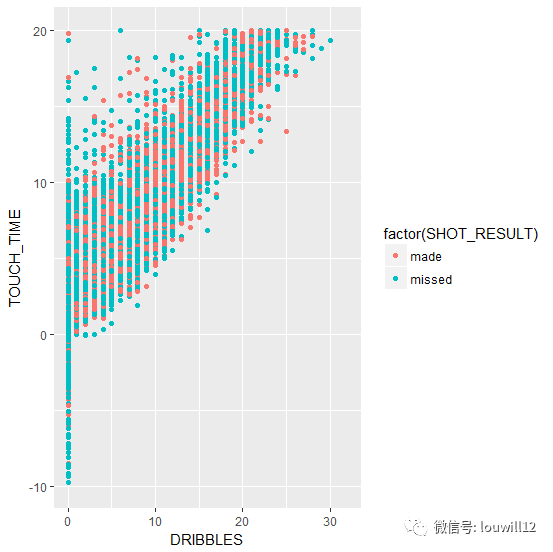
很容易看出,球员的投篮命中率和运球次数、触球时间并没有明显的相关性。NBA球员通常一接到球就投篮(零运球)命中率更高。这也很容易解释,通常战术实施之后,球员出现在空位的概率比较高,无论是远距离三分还是飞身扣篮,命中率都极高。在长时间运球触球的情况下,虽然防守人可以做到针对性强的防守,但此时,大多数球星都能通过运球找到节奏,他们的投篮就比较难防了。参考詹姆斯·哈登和斯蒂芬·库里。此时运球和触球时间明显呈正相关。
主场和客场对球员表现和球队胜负影响大吗?
其实主客场比赛确实有很大的影响,我看了近15年来几乎所有NBA球队的数据统计,发现客场和主场的差距非常明显。当然我说的是勇士、马刺这样的球队,毕竟勇士实力强大到可以忽略客场的存在。下面说说数据,这里我们选取包括主场、客场、投篮命中数FGM在内的变量,通过FGM构造出命中率变量,我们使用dplyr包中的verb函数和管道操作符号进行处理:
(home_away<-nba_shots %>% group_by(LOCATION) %>%
summarise(PERCENTAGE=sum(FGM)/length(FGM)*100))
地方政府办公室
每
离开
44.8117
家
45.6173
从数据分析的结果来看,主客场球队的射门命中率并无明显差异,但0.8个射门命中率的差距也足以扭转比赛局势。我们来看看主客场球队的对比情况:
wins<-nba_shots %>% group_by(GAME_ID,LOCATION) %>% filter(W=='W',FGM
==1)
ggplot(data=wins,aes(LOCATION,fill=factor(W)))+geom_bar()
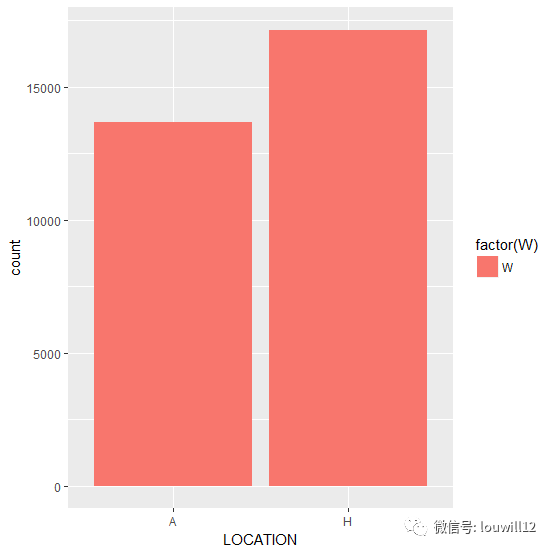
若是对比胜负,那可是千万胜啊!
当今联盟的关键球员是谁?
我们先来看看第一节的得分手。我们使用 dplyr 中的函数过滤掉 == 1, > 5,然后使用函数对球员姓名进行分组,汇总技术统计数据,变换数据框以添加命中率变量,并按降序重新排列变量。我们为这个问题使用了 dplyr 的几乎所有动词函数:
first_quarter_guys<-nba_shots %>% filter(PERIOD==1,SHOT_DIST>5) %>%
group_by(player_name) %>%
summarise(made=sum(FGM),
points=sum(PTS),
total_attempts=length(FGM),
ave_touch=mean(TOUCH_TIME),
ave_distance=mean(SHOT_DIST)) %>%
mutate(percentage=made/total_attempts) %>%
arrange(desc(percentage)) %>% filter(total_attempts>200)
best_1st<-data.frame(first_quarter_guys)
首批伟人发布:
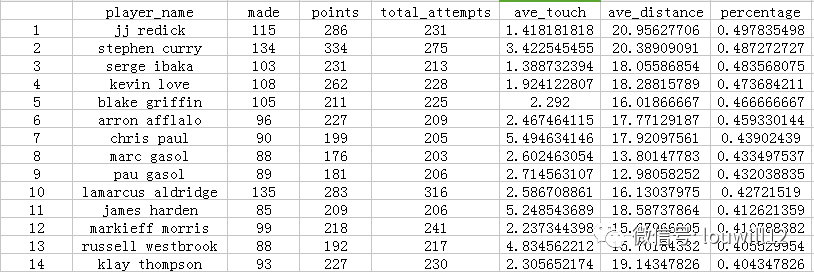
JJ雷迪克是第一节得分最多的球员吗?这和快船的战术有关。第一节,保罗和全队都在寻找雷迪克,投出各种三分球。
如果先赢不算胜利,第一节得分也不重要,那我们来看看决定球队胜负的第四节。联盟中谁是关键球员?同样的做法:
fourth_quarter_guys<-nba_shots %>% filter(PERIOD==4,SHOT_DIST>5) %>%
group_by(player_name) %>%
summarise(made=sum(FGM),
points=sum(PTS),
total_attempts=length(FGM),
ave_touch=mean(TOUCH_TIME),
ave_distance=mean(SHOT_DIST)) %>%
mutate(percentage=made/total_attempts) %>%
arrange(desc(percentage)) %>% filter(total_attempts > 150)
best_4th<-data.frame(fourth_quarter_guys)
关键人物出局了!
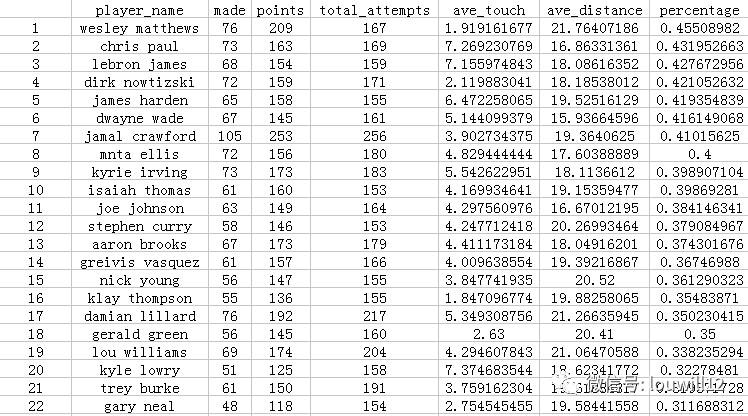
两年前,韦斯利·马修斯是联盟顶级的第四节球员!当时,波特兰以利拉德、阿德、巴图姆、洛佩斯和马修斯为核心的首发阵容实力极强。保罗、詹姆斯、哈登、德克、韦德、贾马尔·克劳福德,这些都是联盟中成名已久的球星。顺便说一句nba球队分布图,两年前路威廉姆斯还是路的爸爸。
谁是最佳和最差防守球员?
这也是来自 dplyr 包的方法。它真的非常容易使用,功能强大!过滤、分组、汇总和重新排列。我们先来看看 NBA 中最好的防守球员:
nba_shots %>%
filter(SHOT_RESULT=="missed") %>%
group_by(CLOSEST_DEFENDER) %>%
summarise(GoodDefense = n()) %>%
ungroup %>%
arrange(desc(GoodDefense)) %>%
head
赛尔吉·伊巴卡
480
德雷蒙德·格林
450
德安德鲁·乔丹
414
保罗·加索尔
400
保罗·米尔萨普
393
马辛·戈塔特
386
都是内线球员,毕竟内线球员的防守数据(篮板+盖帽)是可以直接量化的,伊巴卡在雷霆时期的盖帽,没有夸张。
让我们看看哪些球员的防守更差:
nba_shots %>%
filter(SHOT_RESULT=="made") %>%
group_by(CLOSEST_DEFENDER) %>%
summarise(BadDefense = n()) %>%
ungroup %>%
arrange(desc(BadDefense)) %>%
head
德安德鲁·乔丹
381
保罗·米尔萨普
357
钱宁·弗莱
355
保罗·加索尔
354
武切维奇
335
院长
334
乔丹:你说我的防守好,你又说我的防守差!好的数据去哪了?

哈哈,这里我们只用单一指标来衡量防守,所以评估还比较不成熟。防守数据在NBA很难量化。现在专业的NBA数据分析师有各种先进的数据来衡量球员的防守数据。我们这里只提供参考,重点是数据分析过程。
这个十三万的NBA数据集里有很多东西值得分析和探索,我只选取了自己感兴趣的几个方面进行分析,更多的方面需要自己去探索nba球队分布图,下一篇文章我会在此基础上做一些特征选择和构建以及机器学习算法建模,数据分析和数据挖掘,加油!

相关文章
- 2023-2024 NBA 常规赛排名:东部雄鹿凯尔特人领跑,西部掘金灰熊居前
- 2024 亚冠赛程时间表出炉,你想知道的都在这里
- NBA 2024 选秀大会:法国球员或再度成为状元,追梦格林言论引关注
- 盘点 NBA 历史最强五大高中生:魔兽霍华德与狼王加内特领衔
- 小牛队的历史沉浮:从糟糕战绩到重回季后赛的漫长征程
- 2023 辽宁男篮第三阶段比赛赛程表:冲击季后赛关键赛程
- 哈登:从雷霆替补到超级巨星的华丽蜕变
- 2021 年 6 月 8 日-14 日太阳 vs 掘金比赛综述:太阳 4-0 横扫掘金晋级西部决赛
- 杜兰特出走金州,维斯布鲁克是否难辞其咎?
- 2024 年 3 月 27 日勇士客场挑战热火,双方常规赛最后一次交手精彩纷呈
- NBA2K21 手游汉化版:官方授权正版,WNBA 加入玩法升级
- 2024 年 3 月 18 日 NBA 常规赛赛果及分析:太阳雄鹿激战,热火险胜活塞
- 2024 年 3 月 27 号勇士与热火常规赛最后一次交手,勇士能否止住连败?
- 哈里森-巴恩斯绝杀助小牛连胜,保罗-乔治失常雷霆惨败
- 1 月 3 日 NBA 常规赛:76 人胜公牛,灰熊止连败,鹈鹕取 3 连胜,篮网遭 4 连败